
$262 billion in healthcare claim denials each year is not a billing nuisance. It's a revenue control failure, and a large share is avoidable according to this denial management estimate.
If you're treating denials as routine back-office cleanup, you're already behind. Payers have turned denials, downcoding, and underpayment into a system. Providers need a system too.
My advice is simple. Stop separating denial prevention from denial recovery. In a modern revenue operation, RCM is quality control and IDR is enforcement. One keeps bad claims from leaving the factory. The other forces payment when a payer ignores, discounts, or rejects a valid claim anyway. When those two functions work together, you reduce leakage upstream and recover value downstream.
The True Cost of Unmanaged Denials
Industry sources cite an average initial claim denial rate of 5% to 15%, with 90% considered preventable, and unresolved denials can reduce net patient revenue by as much as 5% according to this healthcare denial management analysis.

That's the number you should care about. Not denial volume by itself. Not how busy your billing team looks. Revenue lost.
Most executive teams still frame denials as friction. They're not. They're a direct hit to cash flow, margin, forecasting, and lender confidence. A denied claim ties up staff time, delays reimbursement, increases write-off risk, and usually exposes a broken process that is hitting more than one claim.
Why this becomes a finance problem fast
Think about denials the way a manufacturer thinks about defects. A defect on one unit is annoying. A defect repeated across thousands of units is a production failure. Healthcare denial management works the same way.
When the same authorization miss, documentation gap, or coding inconsistency shows up repeatedly, your organization is producing flawed claims at scale. The losses aren't isolated. They're systemic.
- Cash gets delayed: Your team works rejections, corrections, and appeals instead of posting payments.
- Labor gets wasted: High-skill staff spend time on rework that should never exist.
- Forecasts get distorted: A/R looks collectible until deadlines pass and denials harden into write-offs.
- Payer behavior gets normalized: If a payer learns you won't fight, it keeps pushing.
Practical rule: If your denial process starts after the ERA arrives, you don't have denial management. You have denial response.
What unmanaged denials really signal
Unmanaged denials usually mean one of three things:
- Front-end controls are weak
- Payer rules are poorly mapped into workflows
- No one owns recovery economics by payer and denial type
That third point matters more than many appreciate. Denials are no longer just a billing problem. They are part of the reimbursement game itself. If you don't measure them as a strategic revenue leak, your payers will.
Redefining Healthcare Denial Management
Most organizations define healthcare denial management too narrowly. They think it means appealing rejected claims. That's outdated.
The better definition is this. Healthcare denial management is your revenue cycle's quality control system. It starts before the patient is seen and doesn't end until you've either collected in full, corrected the root cause, or enforced payment through a downstream dispute path.
Use the quality control mindset
In manufacturing, quality control doesn't wait for a defective product to hit the customer. It builds checks into the line. Registration, eligibility, authorization, documentation, coding, charge capture, claim edits, and contract logic should work the same way.
A strong denial program asks a blunt question at every handoff: what defect can enter here, and how do we stop it before submission?
That changes how you manage the revenue cycle.
- At scheduling, you verify benefit details and referral requirements.
- At registration, you remove demographic and coverage errors.
- Before service, you lock down authorization and medical necessity support.
- Before billing, you validate coding specificity, modifier logic, and documentation integrity.
- After submission, you track payer behavior and attack repeat failure patterns.
Reactive appeals are not a strategy
Appeals still matter. But appeals without upstream control just create organized rework.
Here's the mistake I see constantly. A provider builds a hardworking denial unit that overturns claims one by one, while the same defects keep entering the pipeline. That team looks productive, but the operation is bleeding.
The fastest way to lower denials is to fix where claims are built, not where denials are filed.
What a mature program actually includes
A mature denial function combines prevention, triage, and recovery:
- Prevention controls catch claim defects before submission.
- Root-cause analysis ties denials back to the exact workflow failure.
- Payer intelligence identifies which insurers are applying policy edits, documentation scrutiny, or reimbursement pressure.
- Recovery discipline decides which denials should be corrected, appealed, escalated, or enforced.
This is why I push clients to stop thinking in department silos. Patient access, HIM, coding, billing, contracting, and legal-adjacent reimbursement strategy all sit on the same chain. Break one link and the claim becomes vulnerable.
If you want cleaner claims and stronger downstream recovery, design the claim to survive scrutiny from the start.
Diagnosing Denial Drivers and Payer Behavior
Most denials are not random. They repeat by payer, service line, and failure point. Some industry guidance reports that about 90% are preventable through upstream controls such as eligibility checks, automated authorization workflows, and coding scrubbers, as described in this analytics-focused denial prevention article.
That means your first job isn't “work the denials.” Your first job is classify the pattern.
Generic denial buckets hide the real problem
Teams often group denials into broad labels like eligibility, authorization, coding, or medical necessity. That's useful, but it's not enough to fix behavior. You need to know how those categories express themselves inside each specialty.
An anesthesia group can have a denial labeled “documentation” that really traces back to time reporting inconsistency or modifier handling. An orthopedic practice can get the same label when the actual issue is authorization scope for implants or post-op services. Same top-line category. Different root cause. Different fix.
Here's a practical way to look at it:
| Specialty | Common Denial Reason Code | Typical Root Cause |
|---|---|---|
| Anesthesia | Authorization or documentation denial | Missing pre-service authorization logic, time documentation inconsistency, modifier mismatch |
| Orthopedics | Medical necessity or authorization denial | Procedure-specific authorization gap, documentation not aligned to payer policy, coding specificity issues |
| Gastroenterology | Coding or documentation denial | Incomplete procedure documentation, diagnosis-to-procedure mismatch, modifier use errors |
| Air ambulance | Coverage or underpayment-related denial | Payer policy dispute, benefit interpretation conflict, incomplete supporting records, reimbursement position inconsistent with service facts |
| Hospital outpatient or ASC | Eligibility or claim edit denial | Registration error, coverage mismatch, missing order details, claim scrubber rules not aligned to payer edits |
Track the payer, not just the denial code
The denial code tells you what the payer said. The payer pattern tells you what the payer is doing.
That distinction matters. If one payer consistently denies a service line for “medical necessity” while another underpays the same service after initial acceptance, you don't have a coding issue. You have different payer tactics requiring different responses. This is especially important in specialties where policy-driven reimbursement pressure is common. For a closer look at those tactics, review payer tactics in IDR.
Build a root-cause trail back to the source
I advise clients to trace every major denial cluster back to the originating control point. Use a simple audit path:
- Front desk and scheduling: eligibility, demographics, plan selection, referrals
- Pre-service financial clearance: prior authorization, medical necessity support, benefit checks
- Clinical operations: order integrity, physician documentation, operative note completeness
- Coding and charge capture: code selection, modifiers, diagnosis linkage, claim edits
- Post-bill follow-up: timely correction, appeal readiness, payer escalation
A denial reason is not a root cause. It's a symptom.
Once you map denials this way, one-size-fits-all solutions fall apart. That's a good thing. Broad training won't fix payer-specific authorization failures in orthopedics. A generic scrubber won't solve repeated policy-based underpayments in air ambulance. You need service-line rules, payer-level visibility, and accountability at the exact entry point where the defect started.
Building Your Denial Management Dashboard
Most denial dashboards are cluttered, passive, and almost useless. They display activity, not control.
You don't need fifty metrics. You need a short set of standardized indicators that predict whether cash will arrive, where it will stall, and which payer behaviors are getting worse. HFMA's Claim Integrity Task Force emphasizes the need for standardized denial metrics so organizations can compare performance reliably and segment by payer, service line, and root cause, as outlined in HFMA's guidance on standardizing denial metrics.
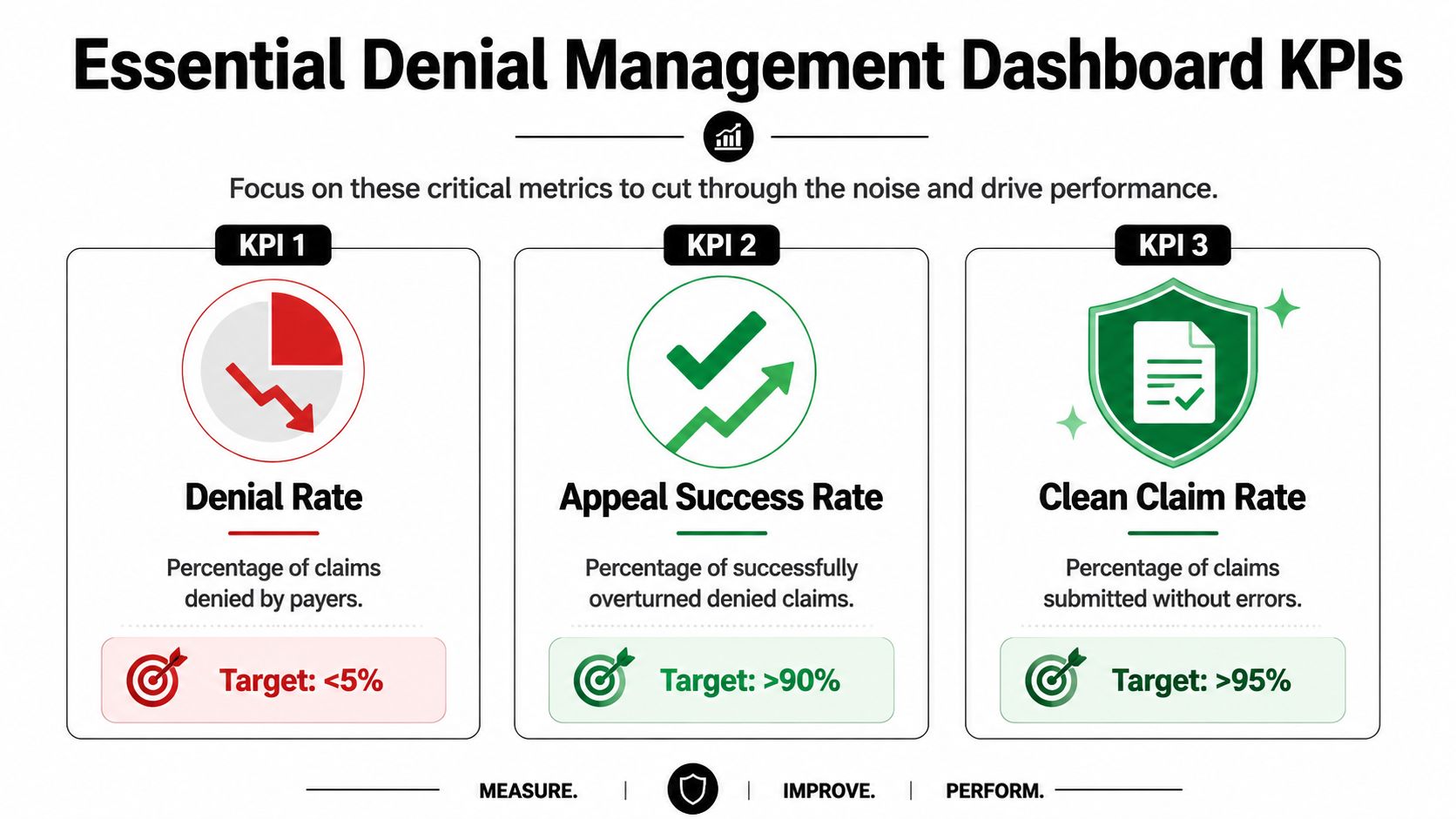
The dashboard should answer four questions
If your dashboard can't answer these quickly, rebuild it.
- Where are denials entering the revenue cycle
- Which payers are driving the highest operational burden
- Which denial categories are most recoverable
- How long does it take your team to turn denials into cash or close them out
The KPIs that actually matter
Start with a compact operating set.
- Initial denial rate measures how many claims are denied on first pass. This is the closest thing to an enforcement trigger for your front-end quality controls. If IDR is your enforcement arm, then IDR acts like revenue enforcement after quality control fails.
- Clean claim rate tells you whether the claim factory is producing submission-ready work.
- Overturn rate shows whether your follow-up and appeal strategy is effective.
- Days to resolution reveals how long denials sit before cash, correction, or loss.
- Payer concentration by denial category tells you where policy friction is recurring.
- Recovery yield by denial type shows which downstream efforts are worth the labor.
The point isn't to admire trends. The point is to make decisions. If one payer produces a low-volume but high-effort denial pattern, that belongs in executive review. If one service line has a strong clean-claim rate but a poor recovery yield, that tells you the problem may be contractual or policy-driven, not operational.
What to cut from the dashboard
Get rid of vanity reporting.
Stop leading with total appeal count, total worked accounts, or generic aging snapshots without payer segmentation. Those numbers often reward effort instead of outcomes. A denial team can look busy while net cash performance declines.
A better dashboard connects operational and financial logic. For example, segment claims by payer, site, denial family, and service line, then review the data in one analytics environment rather than across scattered spreadsheets. Teams evaluating tools for that kind of reporting can look at options such as business analytics platforms for revenue operations.
Standardized definitions matter more than dashboard cosmetics. If one department calculates denial rate differently from another, your benchmark is fiction.
The Integrated RCM and IDR Workflow
This is the part most articles miss. They treat denial prevention and denial recovery as separate disciplines. That split is expensive.
A stronger model connects them. RCM prevents avoidable defects. IDR enforces payment when a valid claim still gets denied, discounted, or underpaid. One is quality control. The other is enforcement.
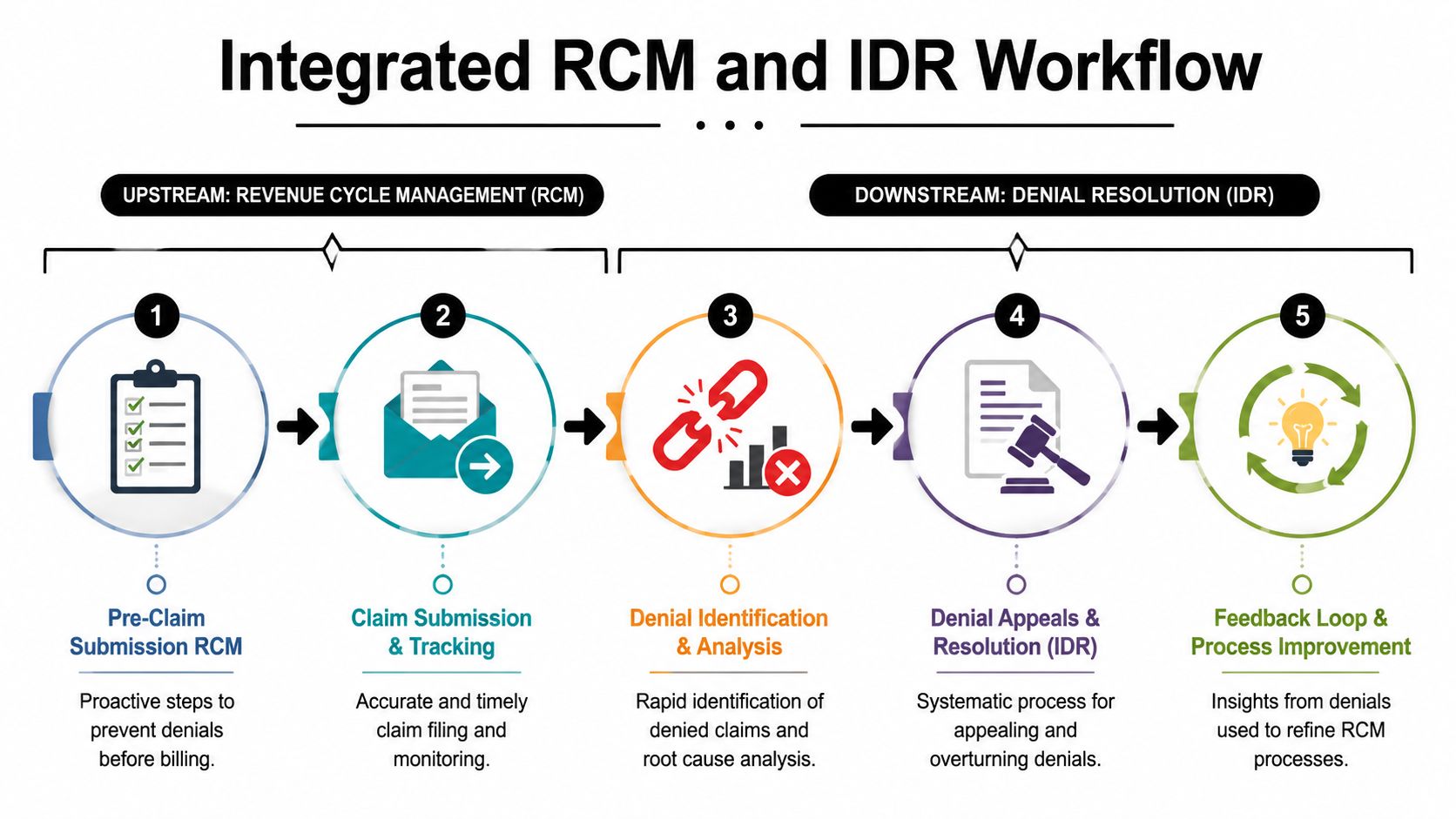
Build claims to be dispute-ready
A clean claim is good. A dispute-ready claim is better.
That means your upstream workflow doesn't just aim for submission acceptance. It also preserves the documentation, coding rationale, authorization history, and payer-facing evidence you may need later if the payer delays, downcodes, or underpays.
Here's the practical sequence:
- Before submission: lock eligibility, authorizations, documentation, coding logic, and contract context
- At submission: ensure clean transmission and monitor payer response quickly
- At denial or underpayment: classify the issue correctly, then decide whether to correct, appeal, negotiate, or escalate
- At resolution: feed every result back into front-end process controls
Why this matters under payment disputes
In specialties exposed to policy disputes or reimbursement compression, the downstream file often wins or loses based on what was captured upstream. Weak records create weak disputes. Incomplete support invites payer discretion.
That's why I tell clients to stop asking, “Was the claim submitted?” and start asking, “If this payer fights payment, can we prove the case fast?”
For a deeper explanation of that connected model, see how RCM and IDR work together.
The feedback loop is where value compounds
An integrated workflow turns every denial and underpayment into operating intelligence.
If appeals repeatedly fail because of a documentation gap, change the documentation standard. If a payer repeatedly applies the same policy logic to one service line, flag those claims earlier and build the supporting record before submission. If a denial family consumes heavy labor but rarely converts to cash, stop overworking it and redirect resources.
This is also where a platform-based partner can help. For example, RevGuard integrates specialty-specific RCM with enforcement-driven IDR and ties both into analytics so teams can link clean-claim workflows to downstream recovery actions. That's the right architecture for organizations that need one operating system instead of disconnected vendors.
Don't design your process around filing claims. Design it around getting paid in full, with evidence ready if the payer resists.
Your Implementation Roadmap
You don't fix healthcare denial management by launching a task force and waiting for monthly reports. You fix it with a controlled build.
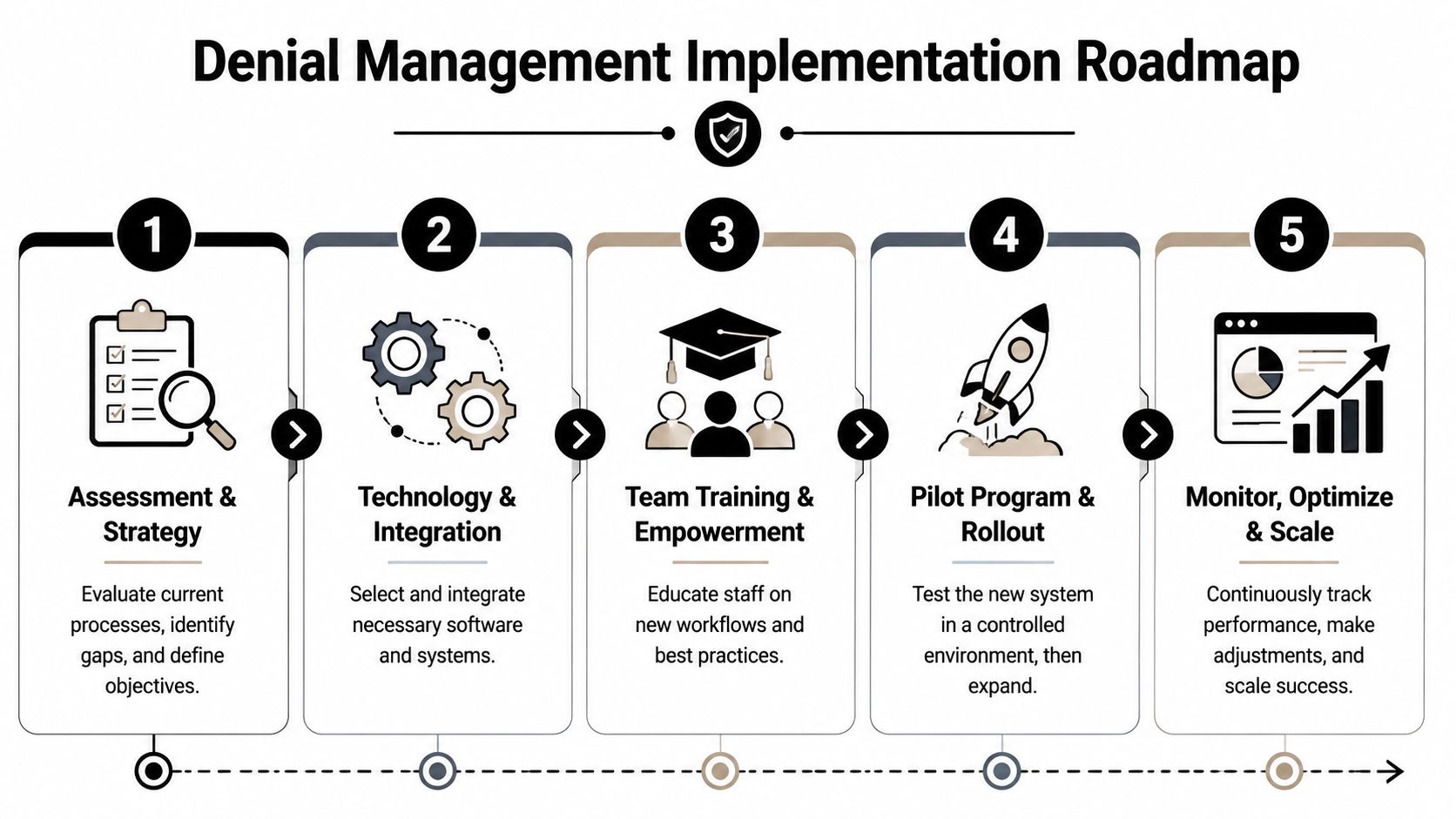
Phase 1 Assessment and baselining
Start with facts, not opinions. Pull a denial inventory by payer, service line, location, and denial family. Then trace the highest-friction patterns back to the originating workflow.
Review these items first:
- Front-end integrity: registration quality, eligibility practices, authorization workflow, referral handling
- Clinical support: documentation completeness, order integrity, operative note standards
- Billing discipline: coding consistency, modifier usage, claim edits, submission timing
- Recovery operations: denial queue logic, appeal readiness, follow-up ownership, escalation rules
Don't debate everything at once. Pick the denial clusters that are repeated, operationally avoidable, and financially meaningful.
Phase 2 Upstream process controls
Now fix the claim factory.
This phase usually requires workflow redesign more than heroics. Tighten registration scripts. Standardize authorization checkpoints. Add documentation prompts where providers routinely leave gaps. Update claim scrubber logic to reflect payer-specific edits. Train coders on the actual denial patterns they're generating, not generic annual refresh content.
A few practical moves work in almost every environment:
- Install pre-bill hard stops for missing authorizations, invalid coverage, and incomplete documentation
- Create payer-specific rule sets instead of relying on generic billing logic
- Assign service-line owners for recurring denial families so nobody can say, “That belongs to another team”
Phase 3 Downstream recovery design
Once upstream controls are tighter, rebuild the denial work queue around recovery economics.
Separate claims into pathways:
- Correct and resubmit when the defect is straightforward and fixable
- Formal appeal when the claim is valid and support exists
- Escalate for dispute strategy when payer behavior points to underpayment, policy misuse, or repeated resistance
- Close out quickly when recovery odds are poor and labor would be wasted
Many groups need automation support at this point. Not because automation replaces judgment, but because it handles routing, status monitoring, documentation gathering, and queue discipline faster than manual spreadsheets ever will.
Phase 4 Pilot, refine, then scale
Don't roll the full model across the enterprise on day one. Pilot it in one specialty, one payer cluster, or one facility where denial pain is obvious and measurable.
Watch for three things during the pilot:
- Adoption gaps: staff may still bypass new controls
- Rule mismatches: scrubbers and workflows often need payer tuning
- Feedback lag: denial insights need to reach front-end teams quickly
When the pilot stabilizes, scale the operating model, not just the software. The workflow, ownership model, and decision rules matter as much as any technology purchase.
Case Outcomes and Measuring ROI
The hardest truth in denial work is this. Winning more appeals doesn't always mean making more money.
One industry source reports that 76% of revenue-cycle leaders spend most of their time on denials, and the better strategy is to target denials most likely to convert into cash after all associated costs are considered, according to this discussion of denial strategy and appeal economics.
Three common provider stories
Air ambulance provider
The organization wasn't dealing with simple typo denials. It was facing repeated underpayments and policy-based resistance. The first mistake was treating every short-pay like a standard denial follow-up item.
The turnaround came when the team separated operational fixes from enforcement cases. Clean claims still mattered, but the larger gain came from identifying payer patterns, preserving support early, and escalating the disputes that had real recovery value.
Multi-state gastroenterology group
This group had recurring coding and documentation denials across multiple sites. Leaders blamed the billing office. The root problem sat upstream. Different providers documented the same procedures inconsistently, and coding outputs varied by location.
The fix wasn't “work harder.” It was standardization. The group tightened documentation expectations, aligned coding review, and used denial patterns to coach the exact sites generating repeat issues. Appeals still happened, but fewer preventable defects entered the system.
Hospital-based anesthesia practice
This practice struggled with reimbursement variance and payer inconsistency. Some claims paid. Similar claims were reduced or denied. Staff treated each account as a unique event, so no one saw the payer behavior pattern.
Once the team started segmenting by payer and denial type, the issue became visible. Some claims needed correction. Others needed formal pushback. A key improvement came from distinguishing isolated billing errors from repeat reimbursement pressure.
How to measure ROI without fooling yourself
Use a practical scorecard.
- Recovered cash: what posted, not what was appealed
- Labor intensity: how much staff effort each denial family consumed
- Cycle impact: whether resolution speed improved cash timing
- Prevention effect: whether the same root cause showed up less often over time
If you only measure appeal volume or gross dollars touched, you'll overvalue busywork. The right ROI model asks whether your combined prevention and recovery system reduced leakage and increased collectible revenue.
The best denial program doesn't fight every battle. It wins the ones that matter, fixes the defects that repeat, and stops paying staff to relive the same mistake.
Healthcare denial management isn't a billing side project anymore. It's a financial control system. Treat RCM as quality control. Treat IDR as enforcement. Link them tightly, and you stop leaking revenue from both ends of the process.